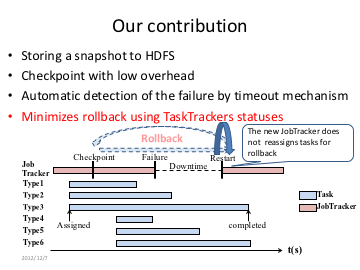
研究内容
ビッグデータ分析の高速化に関する研究

ビッグデータとは,人の行動記録やセンサーの観測結果を収集・貯蔵した膨大な記録情報を表します. ビッグデータは多種多様なデータを未整理のまま収集したものであるため,価値のある情報を発見するデータ分析が必要不可欠です. 近年,IoT(Internet of Things)の普及などにより,世界中で生成される記録データの量と頻度が飛躍的に増大しています. この増大に対応するため,クラスタによる並列分散処理が広く利用されています.
クラスタは,ネットワーク接続された多数の計算機を1つのシステムとして有機的に統合したスーパーコンピュータの1種です. 多数の計算機が協調して動作することで,単一の計算機では容量的・速度的に扱えない問題を実用的な時間内で処理することを可能にします. クラスタを効率良く利用するためのミドルウェアや,その上で実行するビッグデータ分析アプリケーションの高速化について研究しています.
クラスタ向け並列分散処理エンジンに関する研究

クラスタを用いた並列分散処理は高速化の点でとても強力ですが,プログラミングが難しいという問題があります. そこで,部分的なプログラミングのみで並列分散処理を可能にするデータ処理エンジンの研究が盛んです. 並列分散処理特有の処理をユーザから隠蔽・自動化することで,簡便なクラスタ向けプログラミングを提供します. 自動化する部分が多いほどプログラミングは簡単になる一方,高性能を発揮することは難しくなります. 我々は,主に MapReduce と呼ばれる枠組みに着目し,利便性を保ちつつ高速に動作する並列分散処理エンジンの実現に取り組んでいます.
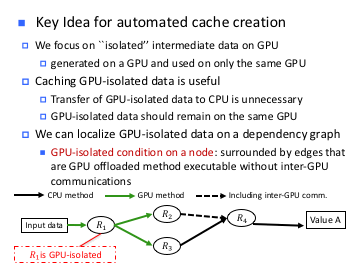
Transparent Avoidance of Redundant Data Transfer on GPU-enabled Apache Spark
Ryo Asai, Masao Okita, Fumihiko Ino, and Kenichi Hagihara
In Proceedings of the 11th Workshop on General Purpose Processing Using GPU (GPGPU 2018), pp.22-30, Vienna, Austria, (2018-02). - [PDF]
Copyright©2018 ACM. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. http://dx.doi.org/10.1145/3180270.3180276
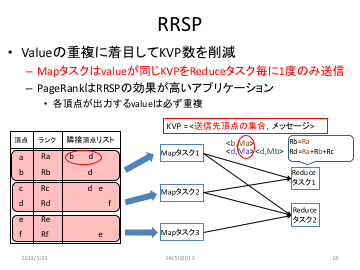
MapReduce を用いたグラフアプリケーションにおける重複メッセージの排除による高速化
黒松信行, 置田真生, 萩原兼一
第11回先進的計算基盤システムシンポジウム論文集 (SACSIS 2013), pp.88-95, (2013-05). 優秀若手研究賞. - [PDF]
Copyright©2013 by the Information Processing Society of Japan. 情報処理学会 電子図書館